练一下文件分析的一些题型,掌握一下Wireshark工具的使用方法
报错版流量包
先做一下第一届 “百度杯” 信息安全攻防总决赛里面的find the flag的这个题,文件地址放这了。
https://static2.ichunqiu.com/icq/resources/fileupload/CTF/BSRC/2017/BSRC3-1/findtheflag.cap用Wireshark直接打开报错了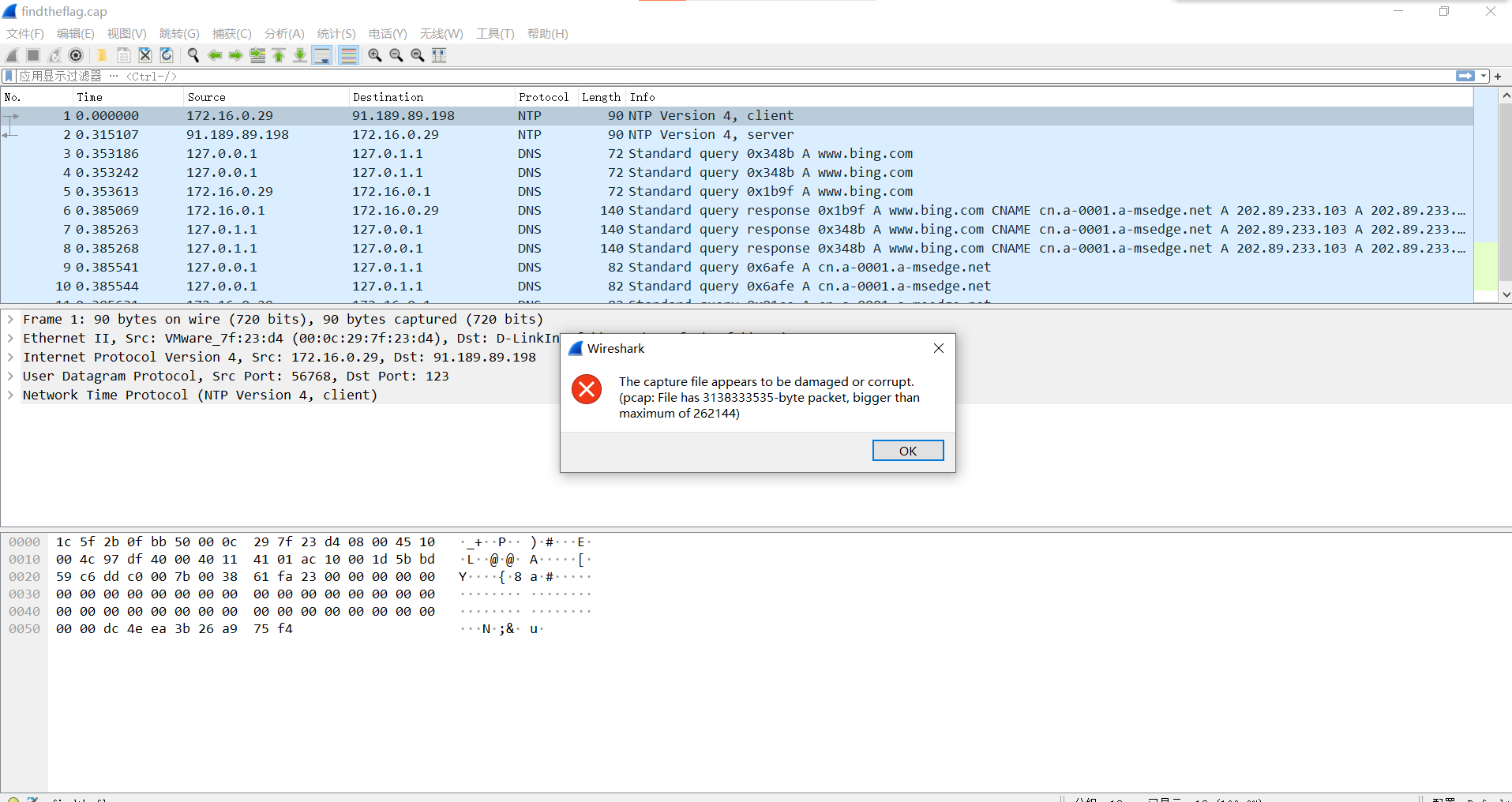
可以使用http://f00l.de/hacking/pcapfix.php修复流量包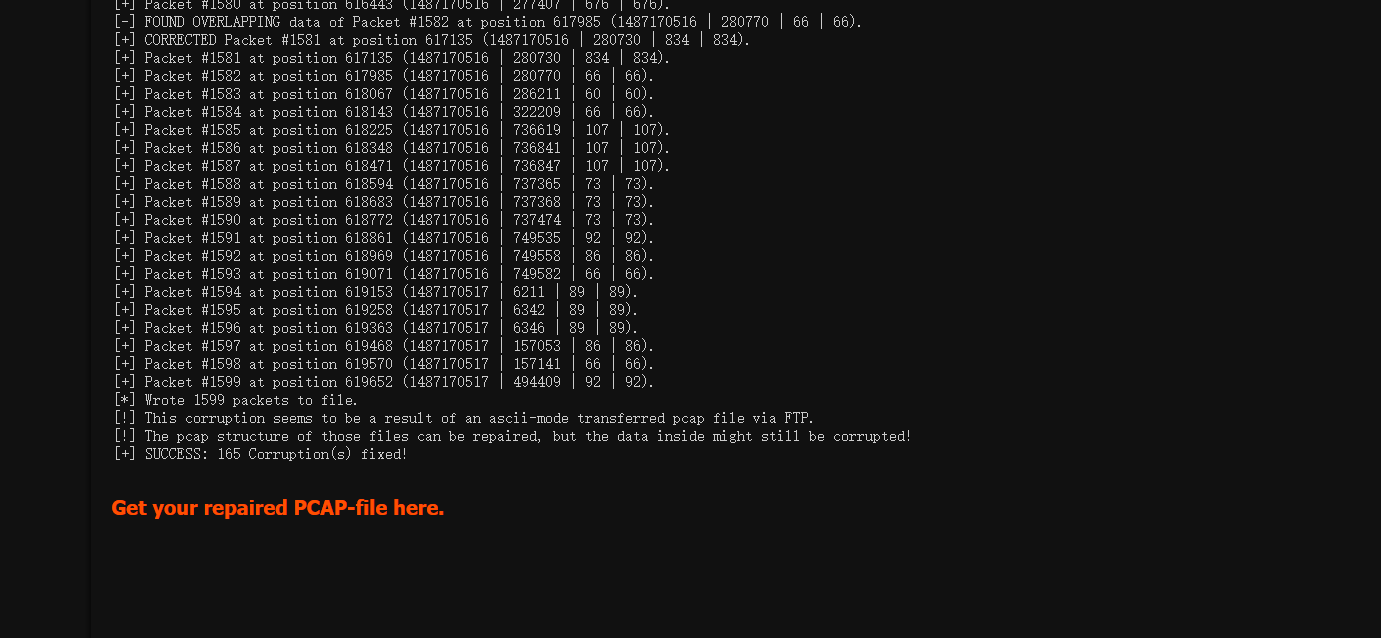
再次打开,在流量包中有提示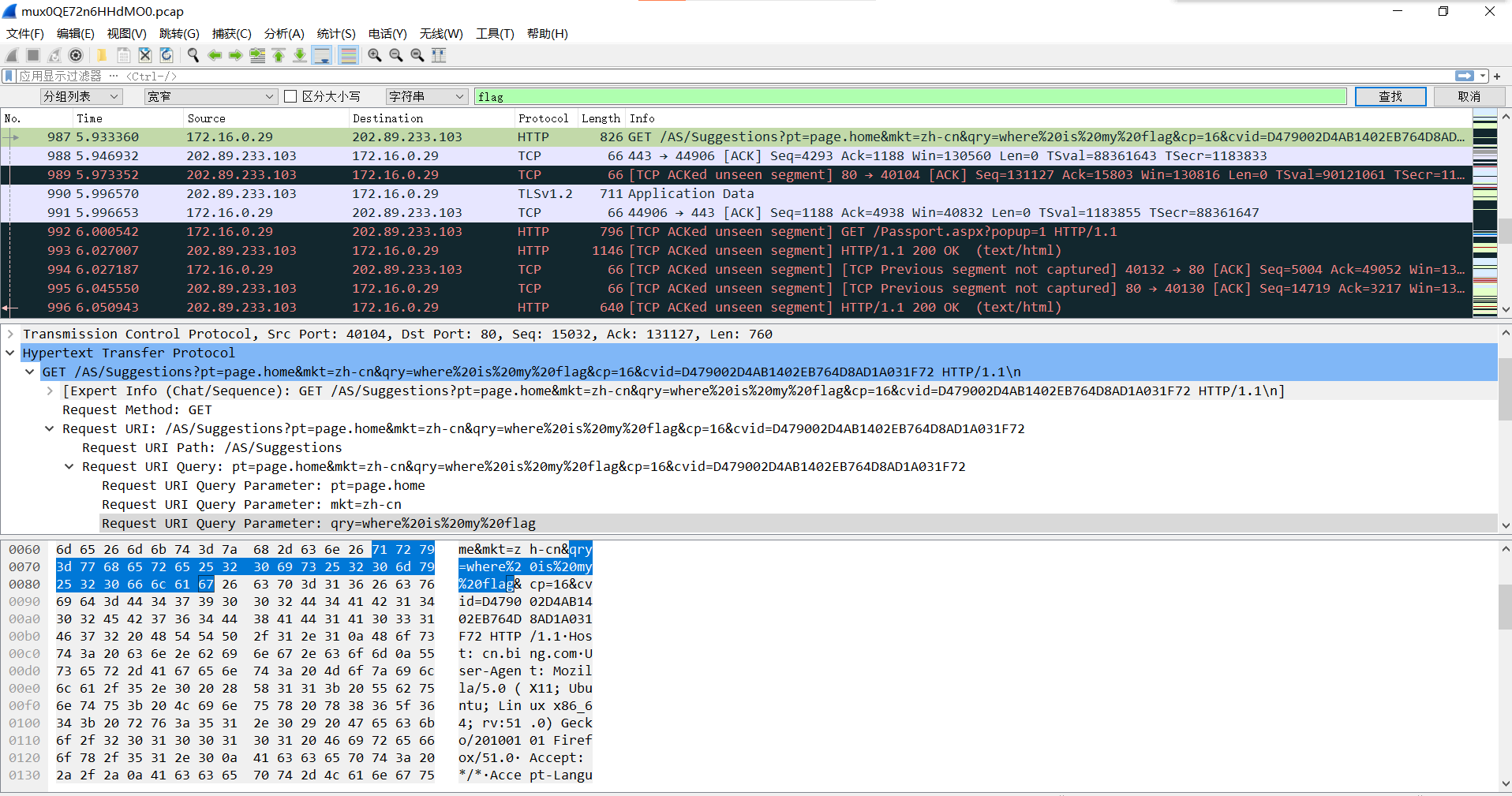
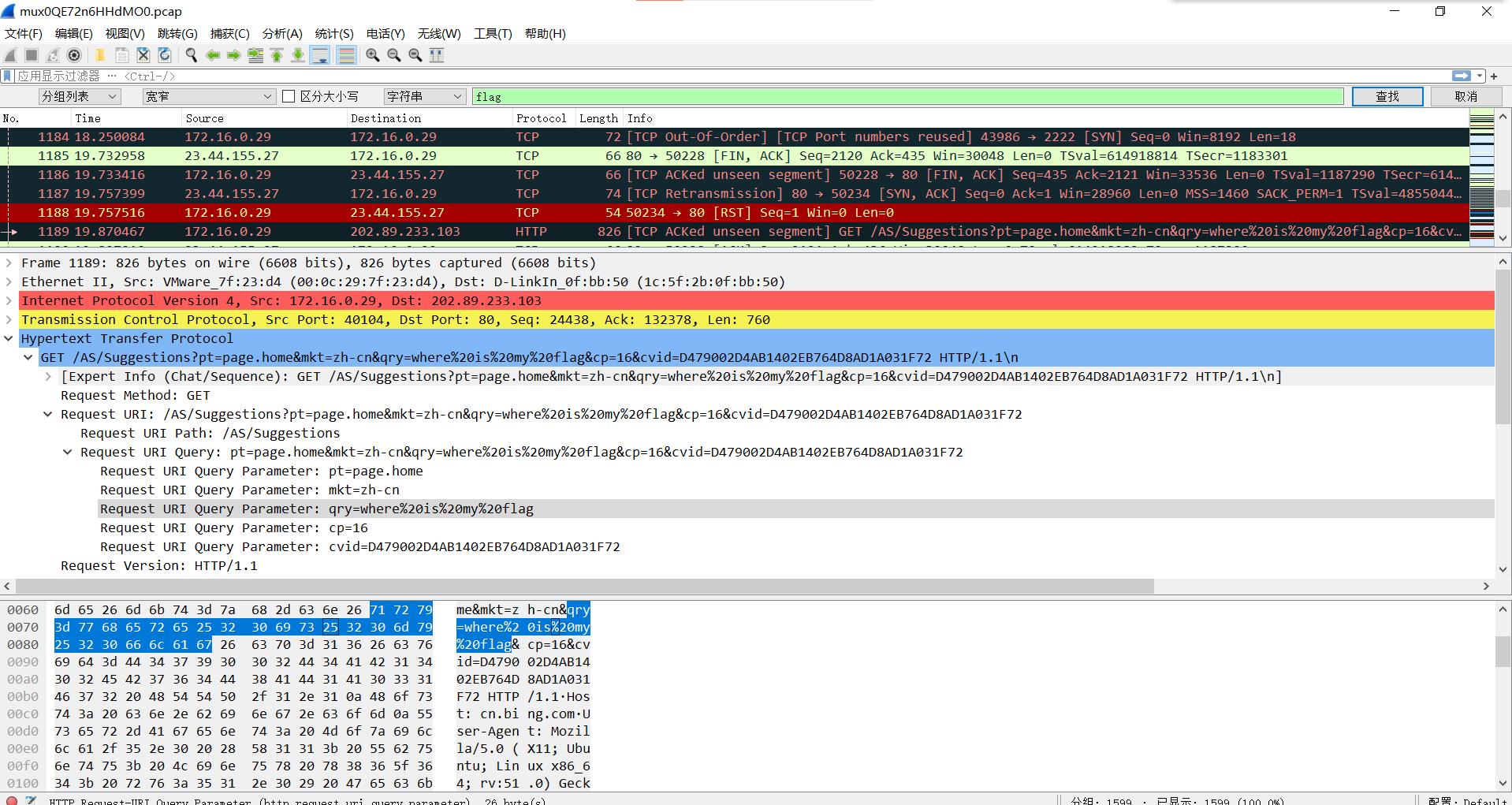
按照同样的方式连接后面相连数据包的id字段,找到最终的flag!
盲注流量-回显全200解法(二分法)
流量分析SQL注入流量
重点去看响应包,也就是HTTP/1.1 200 OK (text/html)里面的内容,如下
Frame 3568: 726 bytes on wire (5808 bits), 726 bytes captured (5808 bits) on interface \Device\NPF_{E6CE0565-F179-4A52-B211-621FF8EEBA4F}, id 0
Section number: 1
Interface id: 0 (\Device\NPF_{E6CE0565-F179-4A52-B211-621FF8EEBA4F})
Encapsulation type: Ethernet (1)
Arrival Time: Feb 14, 2024 20:06:04.593375000 中国标准时间
UTC Arrival Time: Feb 14, 2024 12:06:04.593375000 UTC
Epoch Arrival Time: 1707912364.593375000
[Time shift for this packet: 0.000000000 seconds]
[Time delta from previous captured frame: 0.006990000 seconds]
[Time delta from previous displayed frame: 0.036535000 seconds]
[Time since reference or first frame: 96.515960000 seconds]
Frame Number: 3568
Frame Length: 726 bytes (5808 bits)
Capture Length: 726 bytes (5808 bits)
[Frame is marked: False]
[Frame is ignored: False]
[Protocols in frame: eth:ethertype:ip:tcp:http:data-text-lines]
[Coloring Rule Name: HTTP]
[Coloring Rule String: http || tcp.port == 80 || http2]
Ethernet II, Src: de:75:30:ac:fb:5d (de:75:30:ac:fb:5d), Dst: Intel_b0:5a:45 (38:fc:98:b0:5a:45)
Destination: Intel_b0:5a:45 (38:fc:98:b0:5a:45)
Source: de:75:30:ac:fb:5d (de:75:30:ac:fb:5d)
Type: IPv4 (0x0800)
Internet Protocol Version 4, Src: 117.21.200.176, Dst: 172.16.14.21
0100 .... = Version: 4
.... 0101 = Header Length: 20 bytes (5)
Differentiated Services Field: 0x00 (DSCP: CS0, ECN: Not-ECT)
Total Length: 712
Identification: 0x3f82 (16258)
010. .... = Flags: 0x2, Don't fragment
...0 0000 0000 0000 = Fragment Offset: 0
Time to Live: 49
Protocol: TCP (6)
Header Checksum: 0x0fc3 [validation disabled]
[Header checksum status: Unverified]
Source Address: 117.21.200.176
Destination Address: 172.16.14.21
Transmission Control Protocol, Src Port: 81, Dst Port: 50868, Seq: 1, Ack: 282, Len: 672
Source Port: 81
Destination Port: 50868
[Stream index: 356]
[Conversation completeness: Complete, WITH_DATA (31)]
[TCP Segment Len: 672]
Sequence Number: 1 (relative sequence number)
Sequence Number (raw): 574345654
[Next Sequence Number: 673 (relative sequence number)]
Acknowledgment Number: 282 (relative ack number)
Acknowledgment number (raw): 3857710515
0101 .... = Header Length: 20 bytes (5)
Flags: 0x018 (PSH, ACK)
Window: 501
[Calculated window size: 64128]
[Window size scaling factor: 128]
Checksum: 0xdd9b [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
[Timestamps]
[SEQ/ACK analysis]
TCP payload (672 bytes)
Hypertext Transfer Protocol, has 2 chunks (including last chunk)
HTTP/1.1 200 OK\r\n
[Expert Info (Chat/Sequence): HTTP/1.1 200 OK\r\n]
[HTTP/1.1 200 OK\r\n]
[Severity level: Chat]
[Group: Sequence]
Response Version: HTTP/1.1
Status Code: 200
[Status Code Description: OK]
Response Phrase: OK
Server: openresty\r\n
Date: Wed, 14 Feb 2024 12:06:04 GMT\r\n
Content-Type: text/html; charset=UTF-8\r\n
Transfer-Encoding: chunked\r\n
Connection: keep-alive\r\n
Vary: Accept-Encoding\r\n
X-Powered-By: PHP/7.3.11\r\n
Cache-Control: no-cache\r\n
Content-Encoding: gzip\r\n
\r\n
[HTTP response 1/1]
[Time since request: 0.036535000 seconds]
[Request in frame: 3566]
[Request URI: http://3c97f319-92cf-4ba5-a3f2-6bd644abe921.node5.buuoj.cn:81/search.php?id=1-(ascii(substr((Select(reverse(group_concat(password)))From(F1naI1y)),6,1))%3E31)]
HTTP chunked response
Content-encoded entity body (gzip): 395 bytes -> 708 bytes
File Data: 708 bytes
Line-based text data: text/html (19 lines)
<!DOCTYPE html>\r\n
<html>\r\n
<head>\r\n
<meta charset="UTF-8">\r\n
<title>FLAG</title>\r\n
</head>\r\n
<body background="./image/background.jpg" style="background-repeat:no-repeat ;background-size:100% 100%; background-attachment: fixed;" >\r\n
<div style="position: absolute;bottom: 0;width: 99%;"><p align="center" style="font:italic 15px Georgia,serif;color:white;"> Syclover @ cl4y</p></div>\r\n
\r\n
\r\n
\t\t\t<body background='./image/background.jpg' style='background-repeat:no-repeat ;background-size:100% 100%; background-attachment: fixed;'>\r\n
\t\t\t\t<br><br><br>\r\n
\t\t\t\t<h1 style='font-family:verdana;color:red;text-align:center;font-size:40px;'>ERROR!!!</h1>\r\n
\t\t\t\t</br>\r\n
\t\t\t</body>\t\t\t\r\n
\t\t\t\t\r\n
\r\n
</body>\r\n
</html>重点是里面的Request URI,因为含有注入的url【id=1-(ascii(substr((Select(reverse(group_concat(password)))From(F1naI1y)),6,1))%3E31)】,其次就是回显内容,看Line-based text data,在这里显示的差别就是ERROR!!!
利用下面这个来筛选指定length的流量
frame.len == 978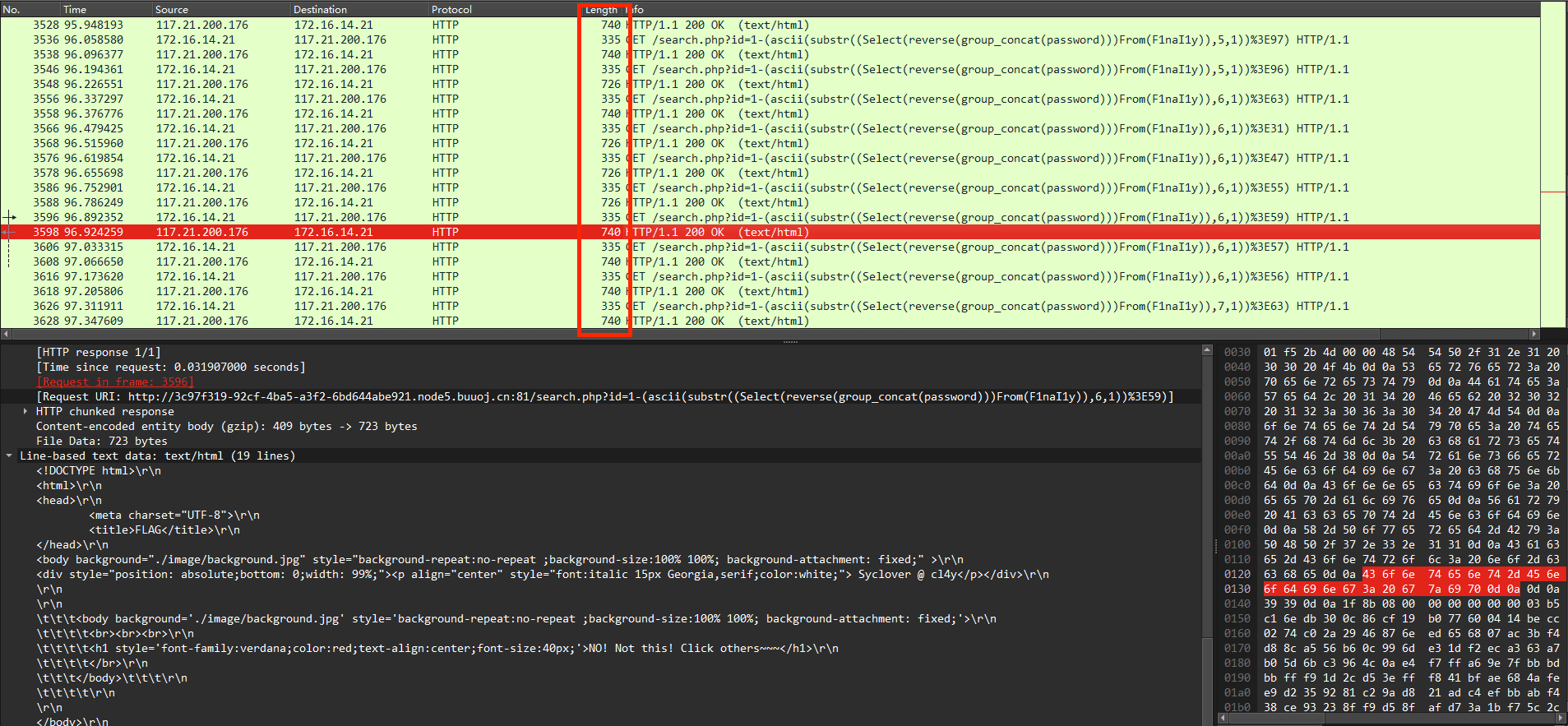
用tshark导出指定内容
┌──(kali㉿kali)-[~/桌面]
└─$ tshark -r blindsql.pcapng -Y "http.request" -T fields -e http.request.full_uri > data.txt然后整理一下只保留有关flag的url
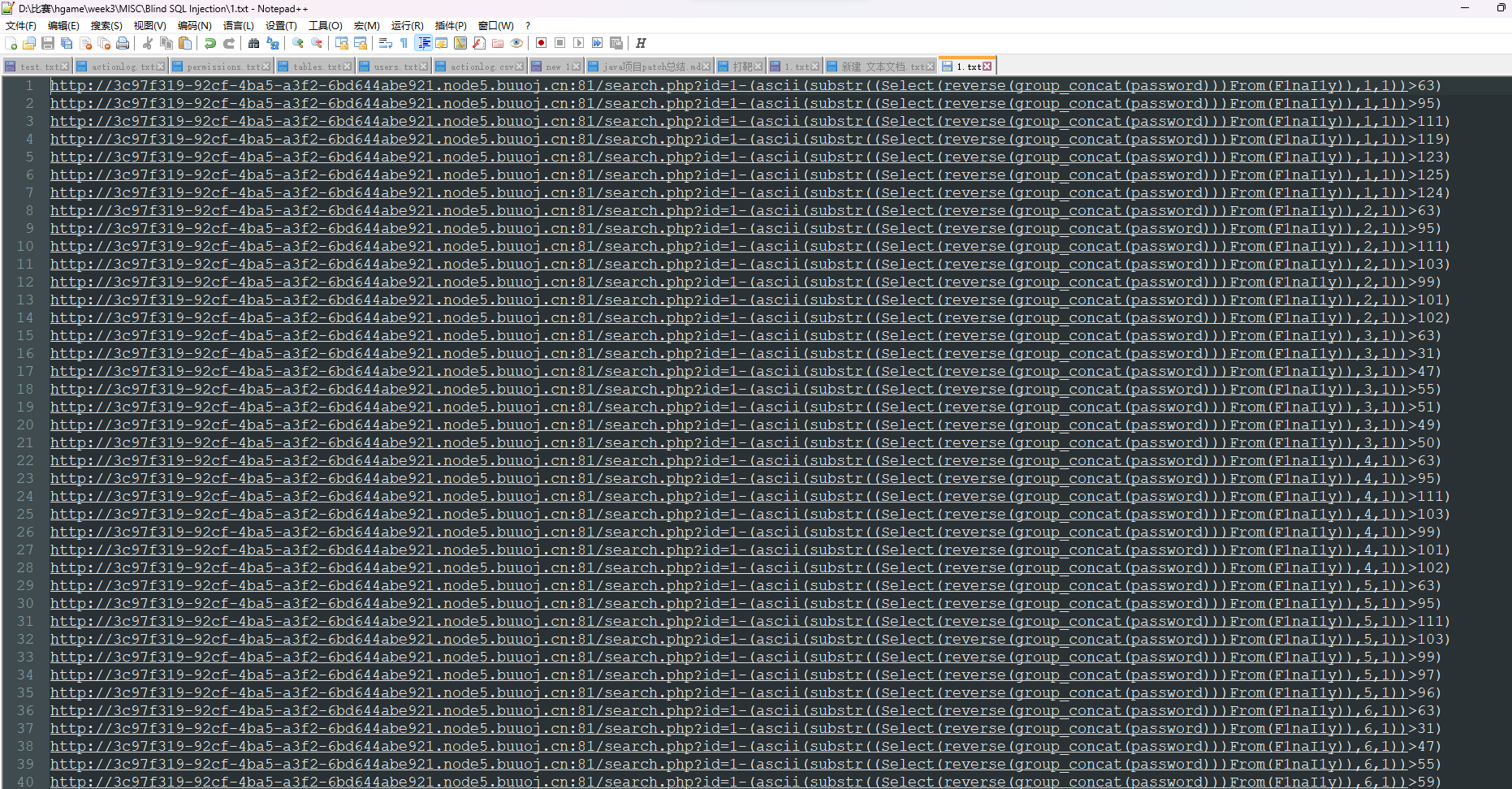
脚本提取
错误率有点高,要不然还是一点一点自己判断吧
import urllib.parse
import requests,re
f = open('1.txt','r',encoding='gb18030',errors='ignore')
lines = f.readlines()
flag_ascii = {}
for line in lines:
if len(line) > 2:
request = urllib.parse.unquote(urllib.parse.unquote(line))
matchObj = re.search(r'''(\d{0,2}),1\)\)\>(\d+)''', request)
# print(matchObj)
#倒数第一的value
# if matchObj:
# key = int(matchObj.group(1)) # key保存字符的位置
# value = int(matchObj.group(2)) # value保存字符的ascii编码
# flag_ascii[key] = value
#倒数第二的value
if matchObj:
key = int(matchObj.group(1)) # key保存字符的位置
value = int(matchObj.group(2)) # value保存字符的ascii编码
# 检查是否已经有一个 value 存在
if key in flag_ascii:
# 如果已经存在,则更新为倒数第二个
flag_ascii[key] = [flag_ascii[key][-1], value]
else:
# 如果不存在,则创建一个列表,并将当前值添加到列表中
flag_ascii[key] = [value]
# # 只保留每个 key 的最后一次出现的 value
# for key, value in flag_ascii.items():
# flag_ascii[key] = value
# print(flag_ascii)
# 获取每个 key 对应的倒数第二个 value
for key, values in flag_ascii.items():
if len(values) > 1:
print(f"{values[-2]}",end=' ')
ascii_value = values[-2]
flag = chr(ascii_value)
# print(str(flag),end='')盲注流量-回显200/404解法(二分法)
当状态码是200的时候,表示正确,报错为404,判断原理为大于num错,小于num+1错,即为num,所以盲注出来的字符串应该是状态码等于200时的字符或等于404时的ascii码减去1
将流量包指定数据筛选后导出
import urllib.parse
import requests,re
f = open('日志里的秘密.log','r',encoding='gb18030',errors='ignore')
lines = f.readlines()
flag_ascii = {}
for line in lines:
if len(line) > 2:
request = urllib.parse.unquote(urllib.parse.unquote(line))
matchObj = re.search(r'''flag_is_here ORDER BY flag LIMIT 0,1\),(.*?),1\)\)>(.*?) AND 'RCKM'='RCKM&Submit=Submit HTTP/1.1" (.*?) ''',request)
#flag_is_here ORDER BY flag LIMIT 0,1),22,1))>96 AND 'RCKM'='RCKM&Submit=Submit HTTP/1.1
if matchObj:
key = int(matchObj.group(1)) # key保存字符的位置
value = int(matchObj.group(2)) # value保存字符的ascii编码
status= int(matchObj.group(3))
print(matchObj.group(3),':',matchObj.group(2))
if status==200:
flag_ascii[key] = value+1 # 用字典保存flag
if status==404:
flag_ascii[key] = value # 用字典保存flag
flag = ''
for value in flag_ascii.values():
flag += chr(value)
print (flag)盲注流量-布尔盲注
import re
#Request URI: http://192.168.246.1/ctf/Less-5/?id=1'%20and%20ascii(substr((select%20flag%20#from%20t),1,1))=102--+
nums = []
obj1 = re.compile(r"1\)\)=(?P<num1>.*)\b",re.S)#开启贪婪模式匹配这里一定要使用.*贪婪模式 如果用.*?可能匹配失败 \b代表结尾
def getAscii():
with open("re.txt", "r", encoding="utf-8") as f:
for line in f.readlines():
line = line.strip()
result = obj1.finditer(line)
for it in result:
num = it.group("num1")
nums.append(num)
def getflag():
flag = ""
for i in nums:
i = chr(int(i))
flag = flag + i
print(flag)
if __name__ == '__main__':
getAscii()
getflag()
盲注流量-时间盲注
import re
#username[1]" = "in ('-1' ))) or if(ascii(substring((select
#flag from flag limit 0,1),1,1))=30,sleep(5),1)
asciis = []
asciis1 = []
obj = re.compile(r"limit 0,1\),(?P<num>.*),1\)\)=(?
P<asciinum>.*)\b,sleep",re.S)
#匹配正则表达式 第一个匹配lit 但是我们需要的只有ascii值 这里用.*贪婪模式 否则匹配失败
def getASCII():
with open("time.txt","r",encoding="utf-8") as f:
for line in f.readlines(): #readlines()读取出来为列表所以我们直接迭代 用strip()去除空格
line = line.strip()
result = obj.finditer(line) #正则匹配
for it in result:
num = it.group("num") #lit值
asciinum = it.group("asciinum") #ASCIi值 注意这里提取的都为str类型 所以以下都要做int强转
asciis.append(asciinum) #将payload的全部ascii值(包括失败的)写入列表
#使用一个循环 时间盲注可知ascii正确后才会进行下一次匹配 所以我们这里直接一个一个循环
# 然后当正确的如102时 下一个又从30开始 所以会比前面小 利用这个特点筛选将正确的ASCIi写入新的列表
def getASCII2():
a = 1
while a < len(asciis):
if int(asciis[a]) < int(asciis[a-1]):
asciis1.append(int(asciis[a-1]))
a += 1
def getFLag(): #转换ASCIi
flag = ""
for i in asciis1:
i = chr(i)
flag = flag + i
print(flag)
if __name__ == '__main__':
getASCII()
getASCII2()
getFLag()
语句为=,而非><
import re
number = []
with open("aa.txt","r",encoding="utf-8") as f:
for i in f.readlines():
flag_number = re.findall(r"\[Request URI: .*?=(\d+)%23\]",i,re.S)
url_list = re.findall(r"\[Request URI: (.*?)\]",i,re.S)
if flag_number:
print(url_list)
number.append(flag_number[0])
print(number)
flag = ''
for i in number:
flag +=chr(int(i))
print(flag)USB键盘/鼠标流量包
在kali,windows不建议,麻烦
python -m pip install poetry
poetry installpython usb-mouse-pcap-visualizer.py -i example/example.pcap
